Mobile Robot Map-Free Navigation
Autonomous Mobile Robots (AMRs) of all forms, which comprise wheeled vehicles, quadrupeds, and humanoids, have the potential to be valuable tools for a variety of tasks in applications that span agriculture, manufacturing, disaster response, search and rescue, military operations, and extraterrestrial planetary exploration. Operation in new and dynamically changing environments without prior maps and those that are GPS-denied, such as caves and lava tubes on Mars, unfamiliar buildings, contested military regions, or areas affected by natural disasters such as fires or earthquakes facilitates the greatest utility, and is unsolved. State-Of-The-Art (SOTA) map-free navigation methods routinely utilize modular techniques that incorporate Simultaneous Localization and Mapping (SLAM) to both estimate the robot's state and construct a map of the environment for collision-free trajectory planning and control. Video 1 shows sped up on-board Visual SLAM (VSLAM) at 0.1 m/s in smooth terrain, and the complete map is illustrated in Figure 1. The construction and maintenance of an explicit human interpretable map introduces a point of failure that renders these systems fragile. Linear and angular velocities beyond a low threshold induce mapping errors due to sensor blur and subsequent feature matching inaccuracies, causing the navigation stack to collapse, necessitating the robot to operate at inefficiently low speeds to maintain localization.
Video 1. Sped up on-board VSLAM.

Figure 1. VSLAM map generated at 0.1 m/s.
To decrease explicit feature extraction and engineering, the full stack perception, planning and control AMR navigation components are encoded in end-to-end Artificial Neural Networks (ANNs) that process controls directly from sensor observations with computationally efficient function approximation that intrinsically models physics [1]. The bottleneck to these methods is the scale of training data, which is time-consuming to gather and incurs high costs. Synthetic data from simulators substantially speeds up the generation of training data, however the physics inaccuracies render simulation to reality (sim-to-real) transfer nontrivial. Motorsport expands the boundaries of technology by pushing vehicles to physical limits to optimize on-track performance [2], which drives automotive innovation, yielding novel vehicle designs, aerodynamics, control systems, and power delivery. Figure 2 illustrates a DRL method [3] to parameterize Out-Of-Distribution (OOD) end-to-end map-free AMR navigation, with a simulated racetrack environment, utilizing large-scale synthetic generation of physical limit training samples [4], with a physics-informed self-supervised throttle maximization objective, replacement of an explicit collision penalty with an implicit truncation of the value horizon to eliminate conservative variance and simulator exploit pruning for zero-shot physical transfer. Spectral spatial densities are encoded as kinodynamic velocity potentials in a computationally efficient, two hidden layer Multi-layer Perceptron (MLP), parameterizing spatial reasoning for map-free exploration and dynamic obstacle avoidance, with robustness in unstructured terrain, shown in Video 2. The policy utilizes on-board sensor observations from cameras or LiDARs, and functions independent of a high-level planner to specify explicit exploration goals, enabling adaptability to new surroundings of varying configurations, autonomy in GPS-denied environments and goal-oriented navigation in multi-light conditions, without computationally expensive state estimation for real-time cartography. Moreover, by using a tenth of the compute required for modular SLAM-based navigation, it is compatible with a range of AMR forms with varying embedded computer payloads.
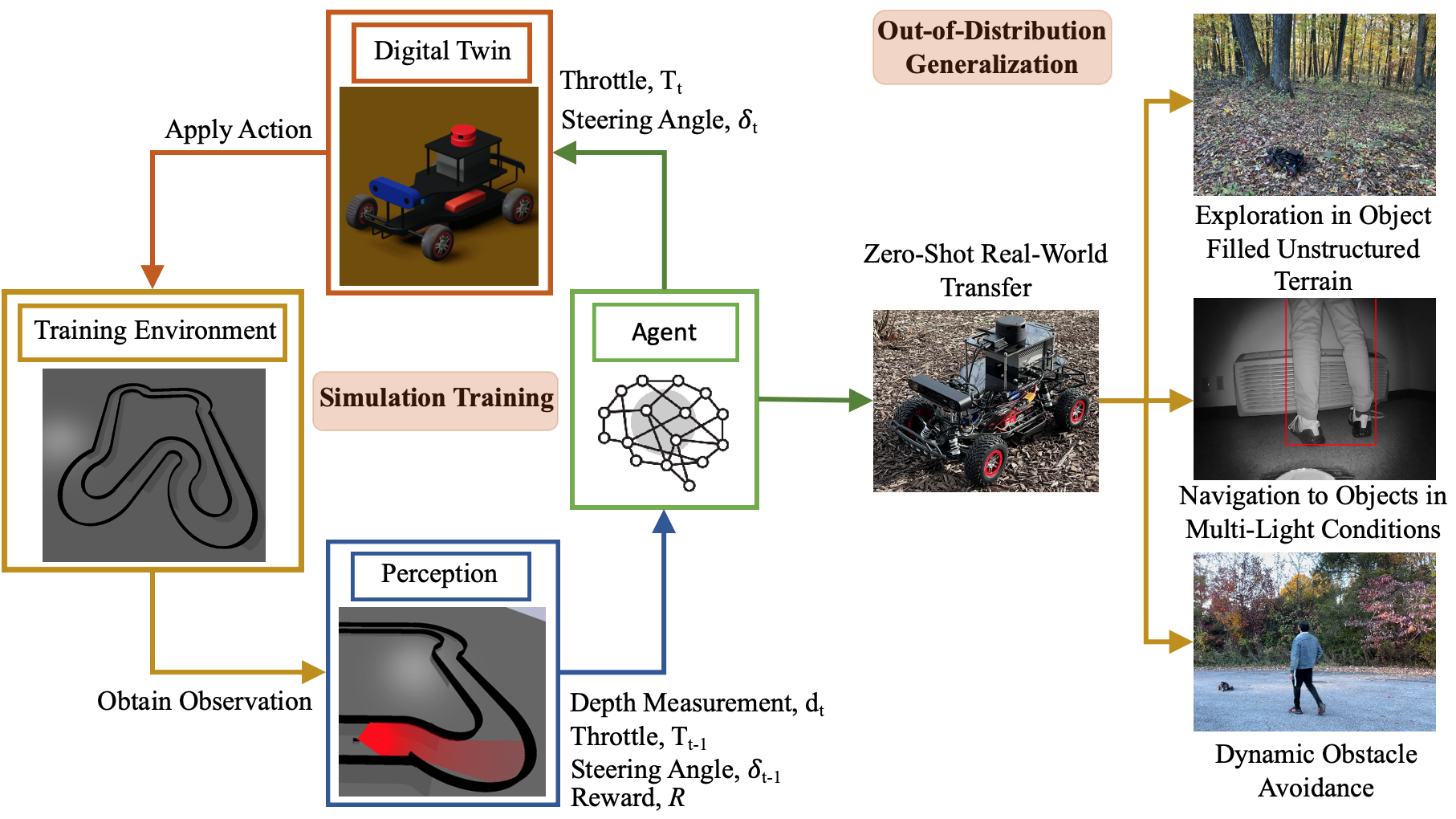
Figure 2. Methodology for map-free AMR navigation with sim-to-real racing parameterized DRL. The policy was trained in simulation to race with a physics-informed simulator exploit-aware reward to parameterize spectral spatial density kinodynamic velocity potentials over 20,000,000 samples and transferred zero-shot to hardware for OOD generalization to exploration in unstructured terrain, navigation to target objects in multi-light conditions, and dynamic obstacle avoidance.
Video 2. Map-free navigation in unstructured terrain and dynamic obstacle avoidance with sim-to-real racing parameterized DRL.
Map-free ANN models without memory which comprise DRL policies and Vision Navigation Transformers (ViNTs), are prone to localized looping when deployed in OOD environments. ViNTs attempt to mitigate this with topological maps constructed from spatially positioned images captured during exploration. The intrinsic exploration parameterized with the racetrack environment transition probability facilities 92% coverage in the environment in Figure 3, assessed by 10 × 10 m2 segments covered by the trajectory, and 56% with 5 × 5 m2 segments, which each represent viable areas to obtain 360◦ Field Of View (FOV) data with on-board sensors. The two hidden layers delineate spatial feature extraction, which compresses the observations to a saturated, information-dense, pseudo-binary geometric vector, and nonlinear kinodynamic planning and control, with functional bifurcation. The 64-dimensional feature encodings from the first hidden layer, that are significantly more efficient than image tokenization, are utilized to compute a latent state temporal sequence of visited locations with a Long Short-Term Memory (LSTM) network to dynamically construct a topological graph for long-term spatial reasoning in parallel to the high-frequency reactive physics of the base DRL policy. A synthetic potential field injects a deterministic spatial bias into the peripheral observation space upon LSTM loop detection, increasing 10 x 10 m2 coverage to 100% and 5 x 5 m2 by 25% to 81%.
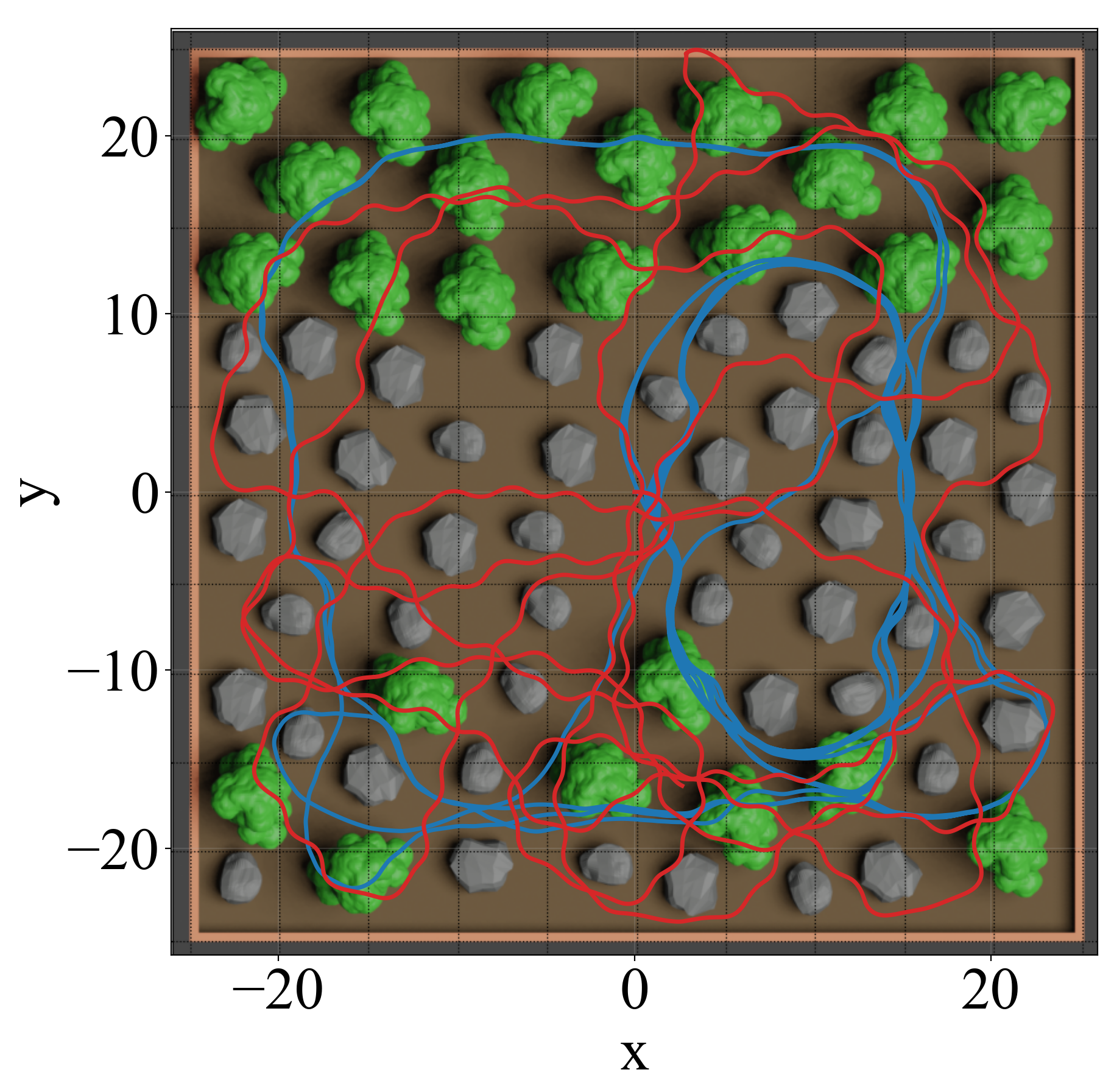
Figure 3. Exploration trajectories with the base DRL MLP policy and LSTM memory augmentation.
Navigation controls, parameterized via time-optimal racing on the Ackermann-steered wheeled platform [5], generalize for cross-embodiment transfer by mapping the continuous action space to high-level linear and angular velocities with a kinematics model. This facilitates map-free obstacle avoidance and exploration on legged robots such as humanoids, shown in Video 3.
Video 3. Cross-embodiment transfer of map-free DRL policy parameterized with wheeled robot racing to a humanoid.
References
[1] S. Sivashangaran and A. Eskandarian, “Deep Reinforcement Learning for Autonomous Ground Vehicle Exploration Without A-Priori Maps," Advances in Artificial Intelligence and Machine Learning, 3 (2), 1198-1219, Jun. 2023. (Link) (Preprint)
[2] S. Sivashangaran, A. Khairnar, S. Gohari, V. Dutta and A. Eskandarian, “Physics-Informed Reinforcement Learning of Spatial Density Velocity Potentials for Map-Free Racing,” arXiv preprint arXiv:2604.09499, Apr. 2026. (Link)
[3] S. Sivashangaran, A. Khairnar and A. Eskandarian, “Mobile Robot Exploration Without Maps via Out-of-Distribution Deep Reinforcement Learning," IFAC-PapersOnLine, vol. 59, no. 30, pp. 533-538, Dec. 2025. (Link) (Preprint)
[4] S. Sivashangaran, A. Khairnar and A. Eskandarian, “AutoVRL: A High Fidelity Autonomous Ground Vehicle Simulator for Sim-to-Real Deep Reinforcement Learning," IFAC-PapersOnLine, vol. 56, no. 3, pp. 475-480, Dec. 2023. (Link) (Preprint)
[5] S. Sivashangaran and A. Eskandarian, “XTENTH-CAR: A Proportionally Scaled Experimental Vehicle Platform for Connected Autonomy and All-Terrain Research," Proceedings of the ASME 2023 International Mechanical Engineering Congress and Exposition.Volume 6: Dynamics, Vibration, and Control. New Orleans, LA, USA, Oct. 29–Nov. 2, 2023. V006T07A068. American Society of Mechanical Engineers. (Link) (Preprint)