Autonomous Racing
Racing entails perception, planning, and control systems that operate at the boundaries of vehicle handling at high speeds. Achieving map-free high-momentum navigation, where the policy infers feasible trajectories and nonlinear dynamics solely from instantaneous sensor data, is a grand challenge. Conventional approaches rely predominantly on detailed prebuilt maps, global reference trajectories, and computationally expensive optimal solvers [1] that are brittle due to localization errors that cascade into the state vector, inhibiting performance, and are inextricably tied to the specific mathematically optimized geometries dependent on reference maps and trajectories that inherently prevents effective Out-Of-Distribution (OOD) generalization. Machine Learning (ML), that comprises Behavioral Cloning (BC) and Deep Reinforcement Learning (DRL), circumvents this by computing the mathematical relation between sensor observations and nonlinear vehicle actuation, facilitating end-to-end control with implicit localization to minimize error propagation, conditioned over a large number of training data samples. BC is a fraction of DRL's performance in simulation, however, since DRL requires a significantly larger scale of training data and collisions at the limit, for parameterization of the best policy that are infeasible without simulation training, BC represents the State-Of-The-Art (SOTA) for end-to-end ML, due to the simulation to reality (sim-to-real) inaccuracies.
A physics-informed reward formulated within an analytically accurate physics engine [2] parameterizes nonlinear dynamics from spectral spatial density velocity potentials, rather than reference trajectory guided geometric occupancy, interpreted from an instantaneous array of depth measurements, in an efficient 2 hidden layer Multilayer Perceptron (MLP) Artificial Neural Network (ANN) with a map-and-model-free DRL policy, that requires less than 1% of the compute of BC and model-based DRL [3], shown in Video 1. Zero-shot sim-to-real transfer is attained with an auxiliary physics engine exploit-aware reward that eliminates slaloming from high-frequency actuation instability, that is a prior inhibitor of sim-to-real transfer in autonomous racing, by addressing a root instability of discrete-time physics engines, which may mathematically permit instantaneous transitions between extreme actuator limits. Despite not utilizing an optimal reference trajectory to guide training, the Proximal Policy Optimization (PPO) policy attains a mean lateral deviation of 0.08% from the optimal minimum curvature path in the training environment, and transfers zero-shot to OOD tracks, maintaining collision-free laps and exhibiting sophisticated racing line anticipation, with an average deviation of 14.60% from the mathematical optimum, depicted in Figure 1. Furthermore, the policy transfers zero-shot to proportionally scaled hardware [4] to lap 26% faster than a Nonlinear Predictive Geometric Proportional-Integral-Derivative (PID) controller that was the fastest method to qualify with 10 collision-free laps at the 2023 IEEE Intelligent Vehicles Symposium, and 12% faster than a human demonstration, that represents a best case BC performance, in OOD tracks, shown in Figure 2.
Video 1. Physics-informed reinforcement learning of spatial density velocity potentials for map-free racing.
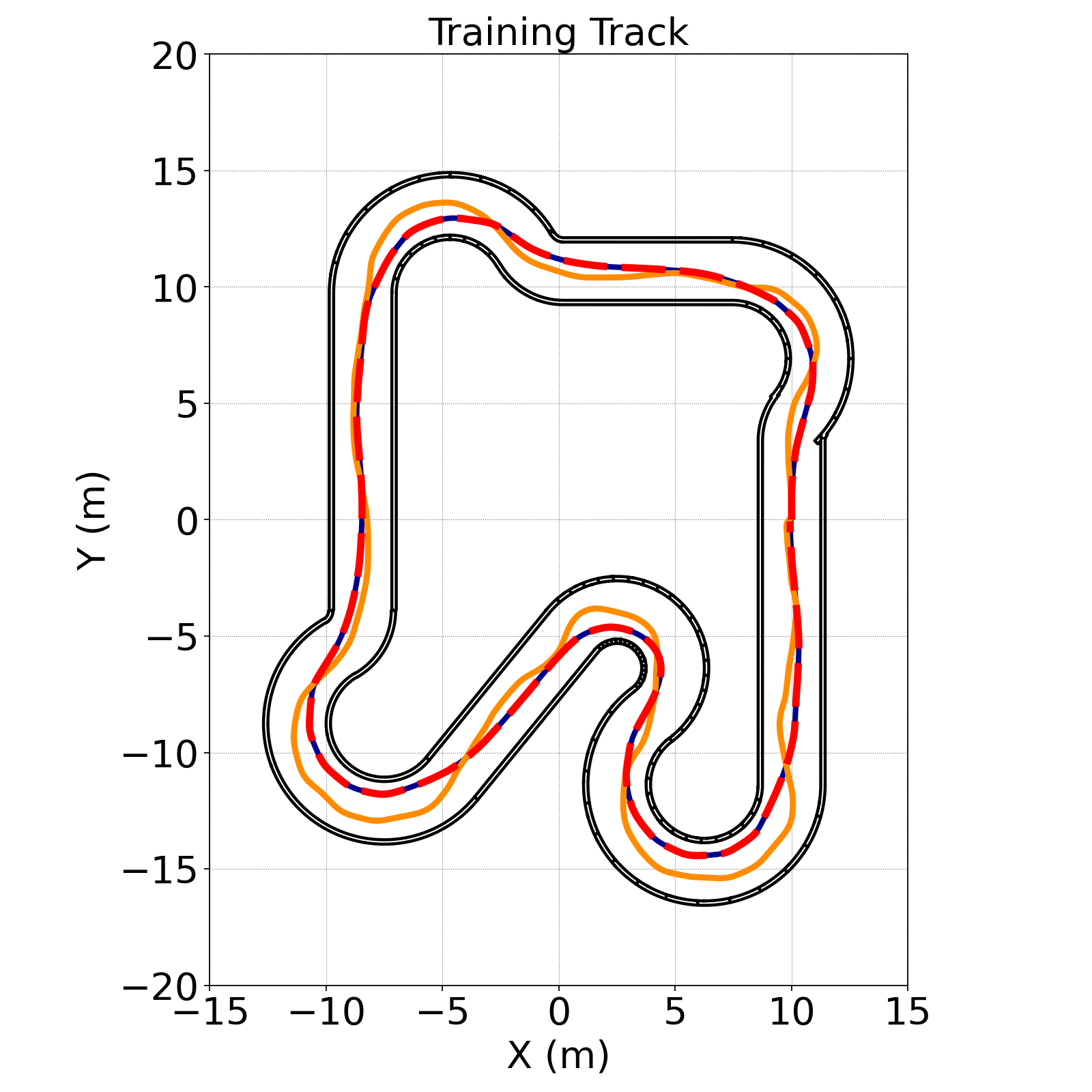

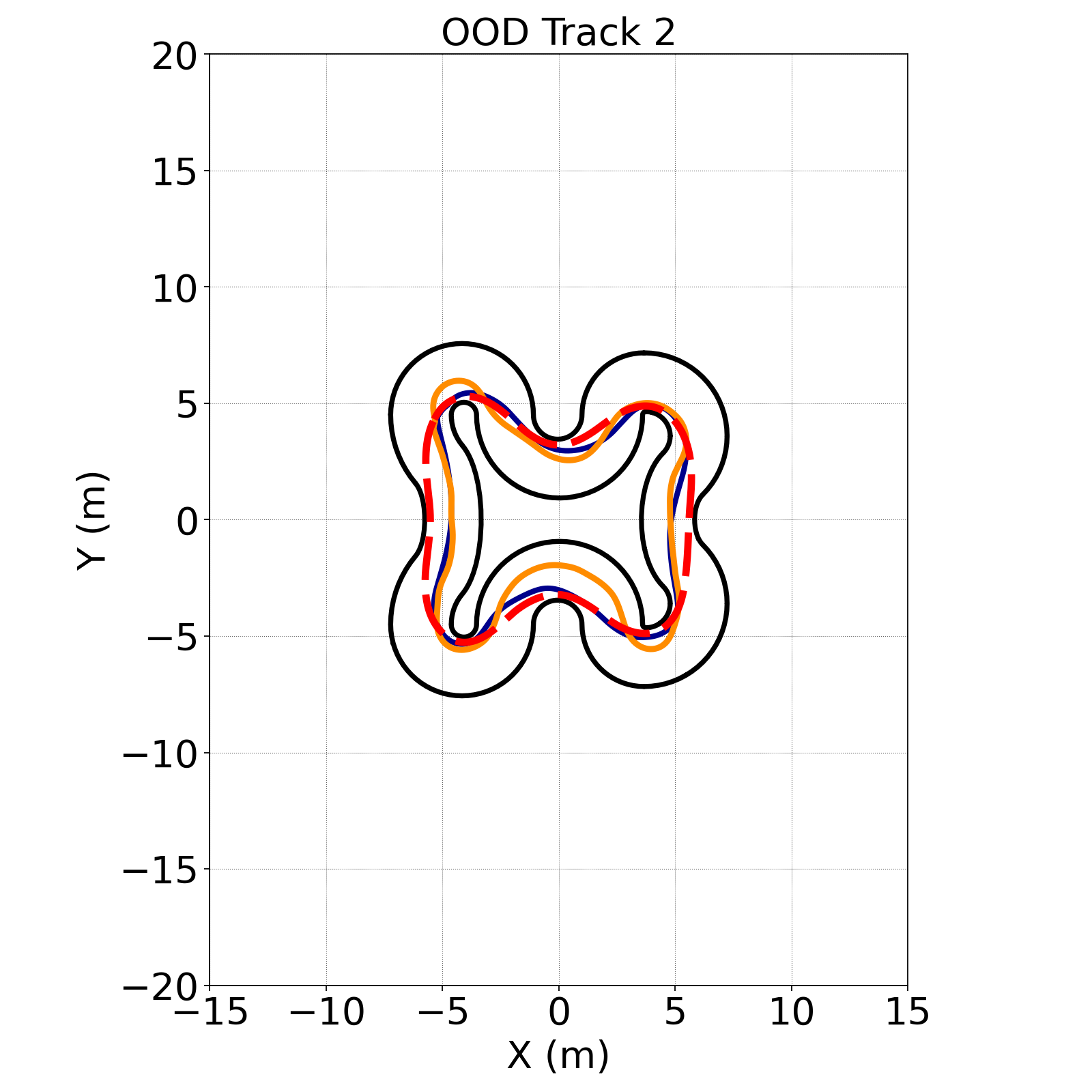

Figure 1. Trajectories in simulated track layouts. (a) Training Track. (b) OOD Track 1. (c) OOD Track 2.



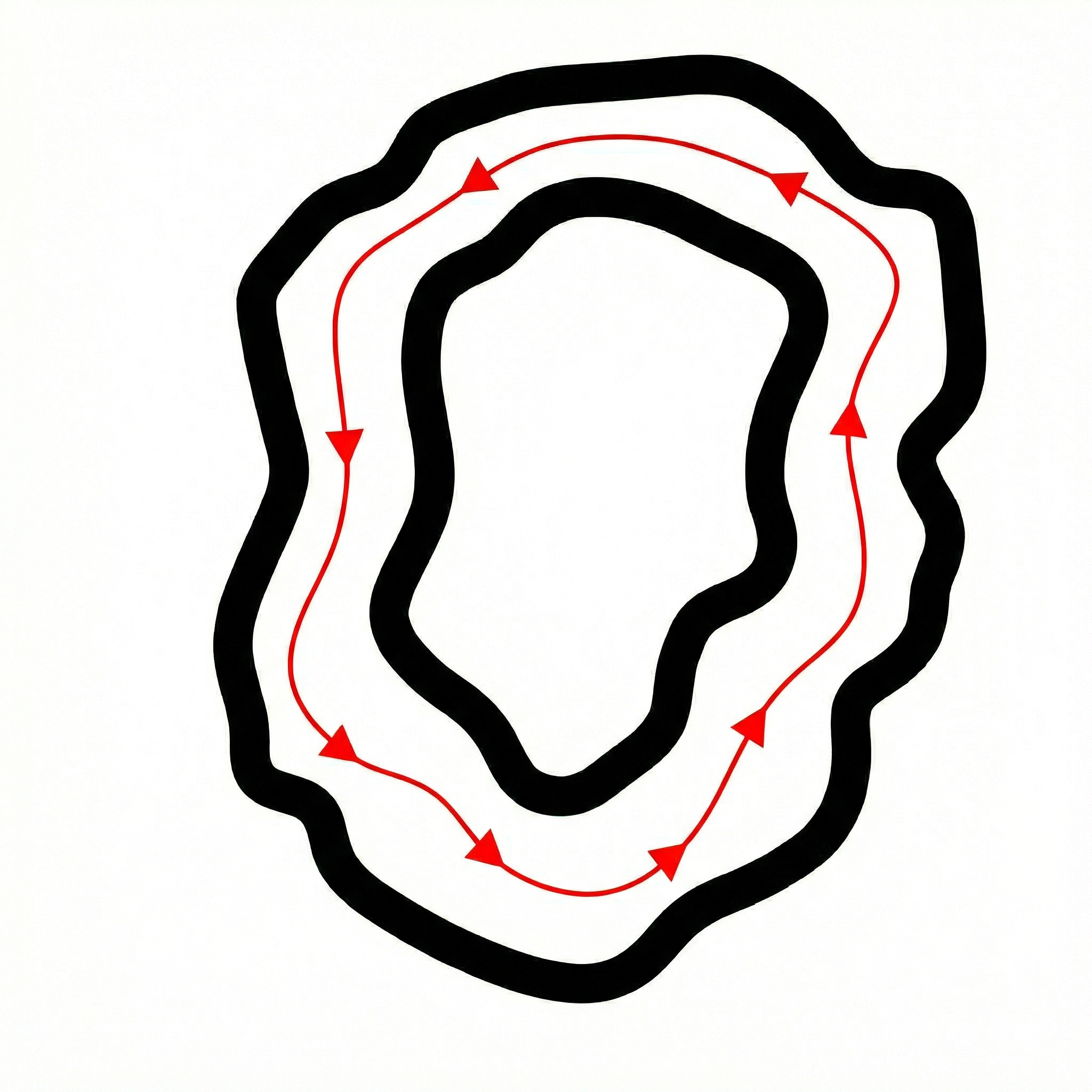


Figure 2. Zero-shot trajectories in OOD physical track configurations.
The adaptability of the physics-informed dynamics encoding facilitates overtaking without specialized multi-agent algorithmic formulations and precomputed reference trajectories. Without altering the core DRL formulation, the policy infers optimized high-momentum overtake trajectories around dynamic obstacle vehicles, with post-training in a multi-agent environment, illustrated by a motion sequence in Figure 3 and the trajectory plots of the overtaking and obstacle cars in Figure 4.




Figure 3. Example of an overtake motion sequence. (a) The overtaking car switches lane to traverse side-by-side. (b) Ahead before the corner apex on the outside. (c) The obstacle car is cleared and the overtaking car navigates back to the racing line. (d) The overtake is complete.
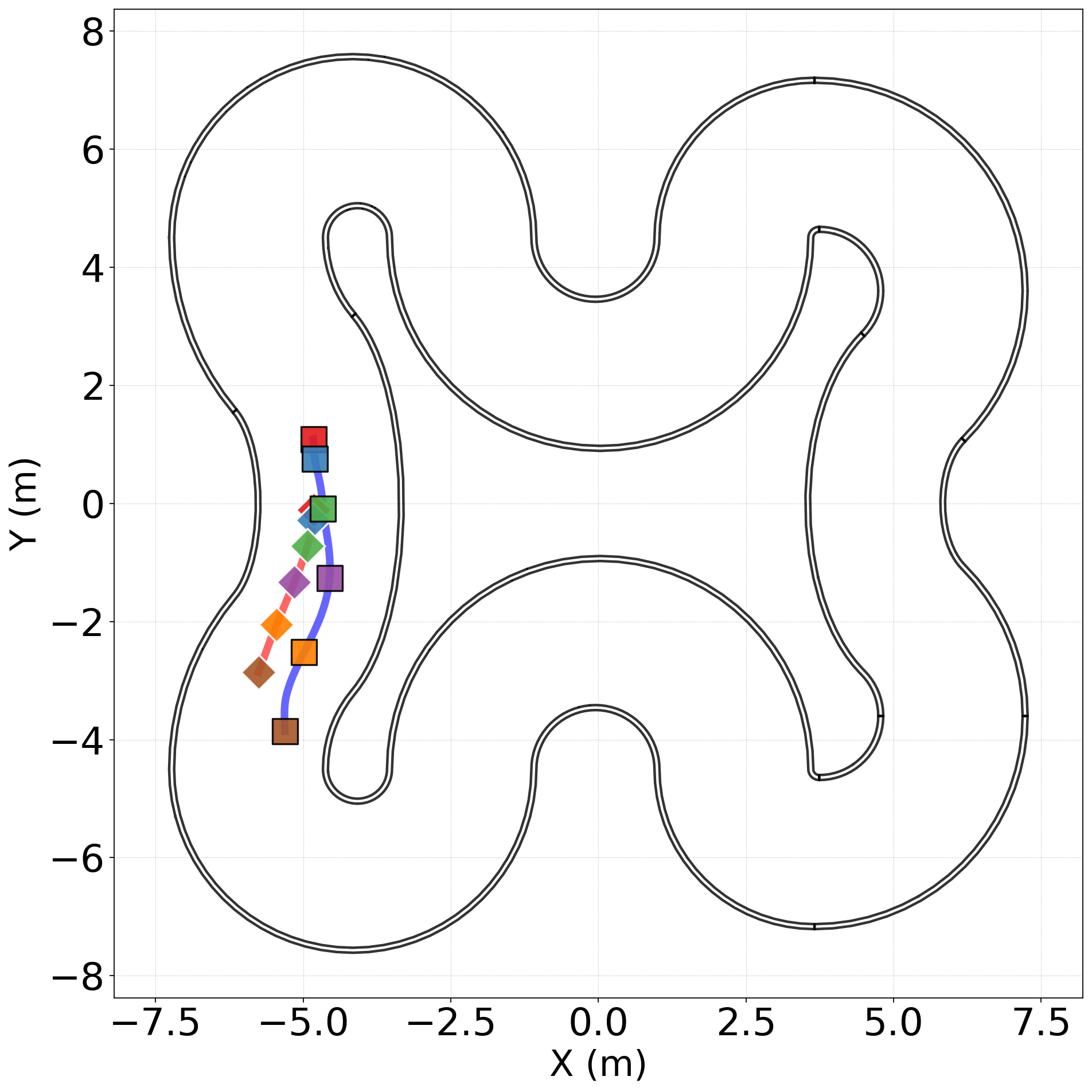



Figure 4. Examples of overtaking trajectories. The positions of the overtaking and obstacle cars are causally color coded.
Dissecting the ANN's internal activations elucidates the internal mechanisms driving the end-to-end framework. By systematically mapping inter-layer correlations with the Pearson product-moment correlation coefficient, a distinct functional bifurcation is identified, where the initial layer operates as a feature extractor that compresses observations to digitized track features with higher resolution in paramount corner apexes, while the subsequent layer encodes nonlinear dynamics, that better fits a nonlinear empirical Pacejka tire model with a coefficient of determination, R2CoD of 0.648 than a linear kinematic model with R2CoD of 0.485, to handle the vehicle at the boundary of the tire friction circle, illustrated in Figure 5 which plots proxies of the lateral acceleration against the slip angle.


Figure 5. Tire dynamics: Lateral acceleration across the slip angle range.
The training environment dynamics and transition probabilities for encoding of relations between spatial observations and velocity potentials with a non-geometric mimicry, physics-informed, simulator exploit-aware reward serve as information-dense proxies for parameterizing AV collision avoidance policies [5], shown in Video 2. Two multi-agent training environment configurations were evaluated, a default uni-direction racing overtaking policy, and a reversed heading variant that generates dynamic, high-momentum oncoming vehicle training samples representative of road AV conflicts. Both DRL policies outperformed a Model Predictive Control and Artificial Potential Function (MPC-APF) baseline across three intersection collision directions on proportionally scaled hardware, depicted in Figure 6 which shows example evasive trajectories with the reversed heading policy. In side collision scenarios where the obstacle vehicle approached Right-to-Left and Left-to-Right, both DRL policies avoided 80% and 70%, exceeding MPC-APF by 10% in each. In the Head-to-Head scenario, which had the greatest relative collision velocity necessitating the fastest decision making, the margins were more substantial, where MPC-APF avoided 10% of collisions, due to the computational latency of iterative optimization, whereas the DRL default overtaking policy improved to 30%, and the reversed heading policy attained 60%, 50% and 30% greater than MPC-APF and the DRL policy trained in the uni-direction environment. The DRL ANN necessitates 30,466 FLOPS and 0.206 ms on the NVIDIA Jetson Orin AGX per control signal, whereas MPC-APF requires 960,000 FLOPS and 13.2 ms, a 31× reduction in compute and 64× reduction in latency that is propitious for real-time evasive control.
Video 2. Autonomous vehicle collision avoidance with racing parameterized deep reinforcement learning.



Figure 6. Trajectories of the ego car, in green avoiding the collision, and obstacle car, in red, on scaled hardware. The obstacle car moves (a) Right-to-Left (b) Head-to-Head (c) Left-to-Right.
References
[1] S. Sivashangaran, D. Patel and A. Eskandarian, “Nonlinear Model Predictive Control for Optimal Motion Planning in Autonomous Race Cars," IFAC-PapersOnLine, vol. 55, no. 37, pp. 645-650, Nov. 2022. (Link)
[2] S. Sivashangaran, A. Khairnar and A. Eskandarian, “AutoVRL: A High Fidelity Autonomous Ground Vehicle Simulator for Sim-to-Real Deep Reinforcement Learning," IFAC-PapersOnLine, vol. 56, no. 3, pp. 475-480, Dec. 2023. (Link) (Preprint)
[3] S. Sivashangaran, A. Khairnar, S. Gohari, V. Dutta and A. Eskandarian, “Physics-Informed Reinforcement Learning of Spatial Density Velocity Potentials for Map-Free Racing,” arXiv preprint arXiv:2604.09499, Apr. 2026. (Link)
[4] S. Sivashangaran and A. Eskandarian, “XTENTH-CAR: A Proportionally Scaled Experimental Vehicle Platform for Connected Autonomy and All-Terrain Research," Proceedings of the ASME 2023 International Mechanical Engineering Congress and Exposition.Volume 6: Dynamics, Vibration, and Control. New Orleans, LA, USA, Oct. 29–Nov. 2, 2023. V006T07A068. American Society of Mechanical Engineers. (Link) (Preprint)
[5] S. Sivashangaran, V. Dutta, A. Khairnar, S. Gohari and A. Eskandarian, “Autonomous Vehicle Collision Avoidance With Racing Parameterized Deep Reinforcement Learning,” arXiv preprint arXiv:2604.16702, Apr. 2026. (Link)